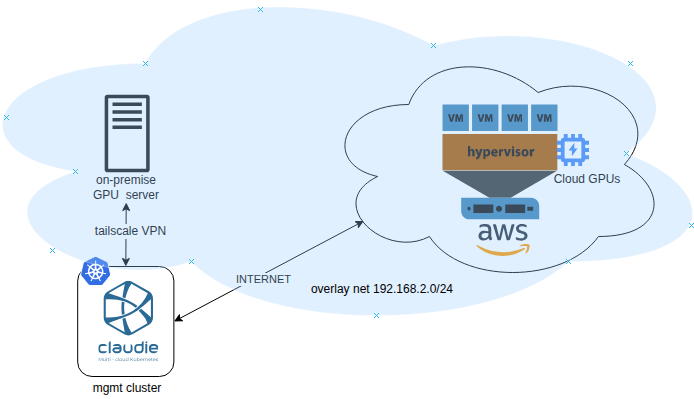
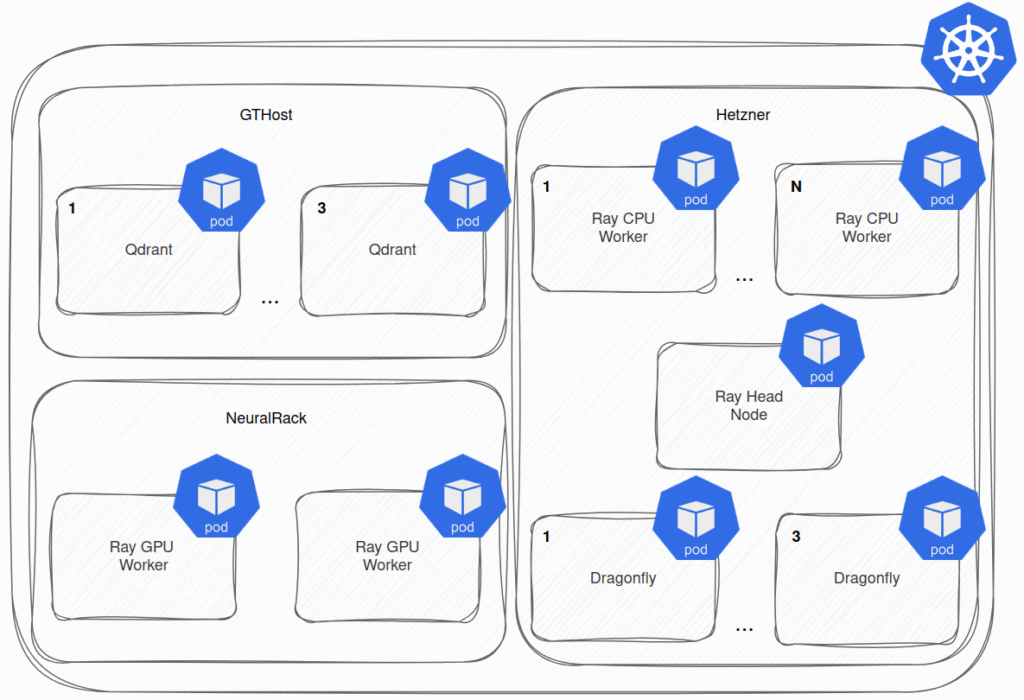
In this blog post, we would like to share our experiences running AI applications on Kubernetes. Our client, Mixedbread, leverages KubeRay Operator to run their AI workloads. We help them migrate their applications from one of the hyperscalers to a multi-cloud solution using an open-source tool named claudie.io, and cut the infrastructure cost by 70%.
That, however, is a different part of the story and not the focus of this article. As we mentioned before, part of our delivery involved the application migration. Their tool of choice for the AI workloads was KubeRay Operator, specifically the RayCluster component. For those who may not be familiar with RayCluster, here’s a brief overview.
Picture it as a cluster whose nodes run as pods in the Kubernetes cluster, and they are optimized to run AI workloads. Using the KubeRay Operator, you can utilize the RayCluster Custom Resource Definition (CRD) for spawning RayClusters across the K8s cluster. However, these clusters are initially idle, and the application deployment is left up to you.
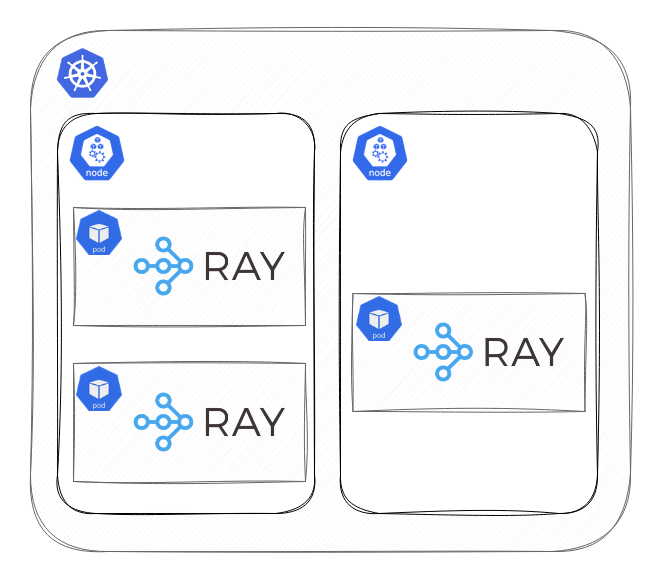
Ray has a concept known as jobs. These are essentially one-time processes with a distinct start and finish. They can either run some application logic or deploy something called Ray Serve Deployment. To make this easier to grasp, envision the Ray Serve Deployment as a Kubernetes Deployment but operating inside the RayCluster rather than on Kubernetes directly.
As you might have already noticed, the Ray Serve Deployment represents one of the methods to run applications serving API servers within the RayCluster. Folks from Mixedbread used to deploy their REST API applications using the Ray CLI, but they wanted to transition away from this approach since it has several disadvantages.
For instance, it was unclear who ran the command, what configuration they used, and there was a risk of multiple people executing it simultaneously. The KubeRay operator provides a RayJob CRD that contains all the necessary configuration, including dependencies, environment variables, and a reference to the application ZIP file for deployment. Wait, did you say reference to the application ZIP file?
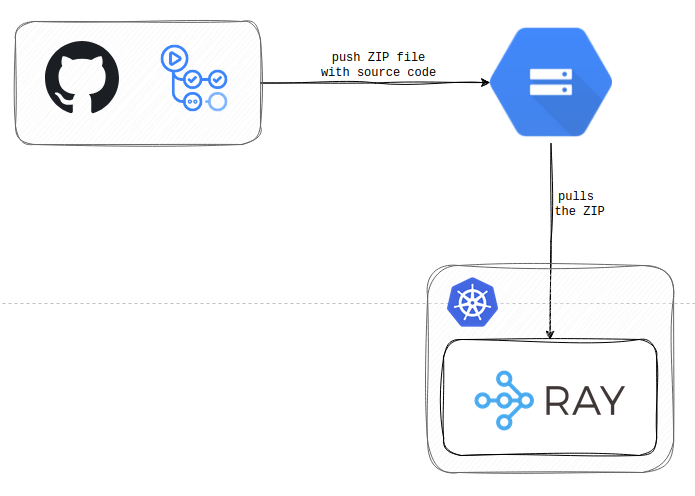
Yes, we did. In RayJob, you don’t use an OCI image to pull application source code. And this was the first thing that made us think, why would somebody design it like this? But it is what it is, right? We set up a pipeline that builds a ZIP file with all the application’s source code instead of the OCI image. These ZIP files are subsequently pushed to the Google Storage Bucket (storage options for your ZIPs are limited by the KubeRay Operator), from which they are pulled by the KubeRay Operator during the deployment.
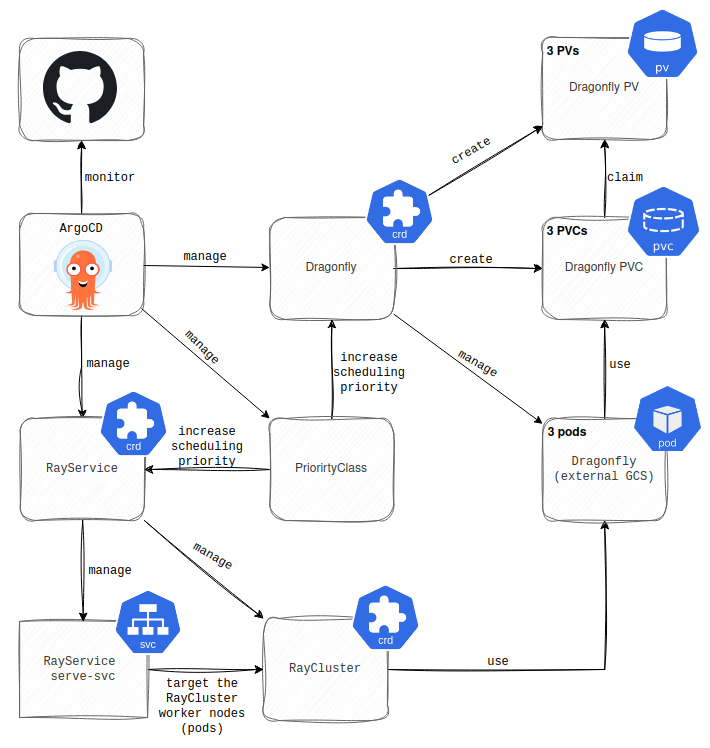
Because we wanted to track the deployment changes and offload the deployment process to a central authority, we utilized ArgoCD. ArgoCD monitors the dedicated repository with the RayJob Custom Resource (CR) configuration and recreates this CR upon detecting a change. The RayJob CR then creates a K8s Job that deploys the Ray Serve Deployment (running Mixedbread’s actual application) to the RayCluster.
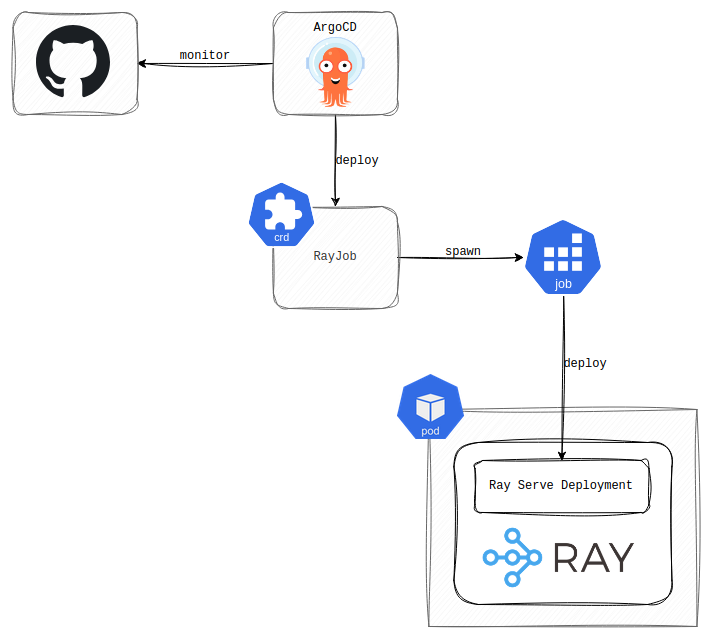
The challenging aspect is that the RayJob CR reports on the success of the initial deployment, but does not monitor the ongoing status of the Ray Serve Deployment. Consequently, if the Ray Serve Deployment vanishes, K8s remains unaware, and ArgoCD will not reconcile the RayJob to redeploy it. So, why am I bringing this up? What would cause Ray Serve Deployment to disappear from the RayCluster? Well, the RayCluster head node. This node runs a Global Control Service (GCS) that stores the state (deployed applications, run jobs, etc.) of the RayCluster. Since the head node runs as a pod, and we know pods are ephemeral, it can be deleted at any moment. The KubeRay Operator manages the restarts of the RayCluster’s head node after deletion, but the RayCluster’s state stored in the GCS is lost. As a result, the RayCluster reconciles, but you are faced with an outage because the applications running in the Ray Serve Deployments have vanished and will not return until you redeploy them.
Unfortunately, RayCluster supports only one head node, meaning you can’t improve resilience by increasing the number. However, the creators considered this and came up with an external GCS for the fault tolerance. By using the external GCS, you can store the state of the RayCluster outside of the head node and load it automatically following the head node restart. We encountered one issue with this method, though. Updates to the application’s dependencies running in the Ray Serve Deployment weren’t reflected. What I mean is that the Ray Serve Deployment was deployed successfully by the RayJob CR, but the actual application running there didn’t function correctly because it lacked a newly added dependency that hadn’t been installed. Eventually, we abandoned the external GCS approach and implemented a custom solution with Argo Events and Argo Workflows to spawn an Argo Workflow that deletes the RayJob CR whenever the head node restarts. ArgoCD syncs the RayJob CR; it gets recreated automatically.
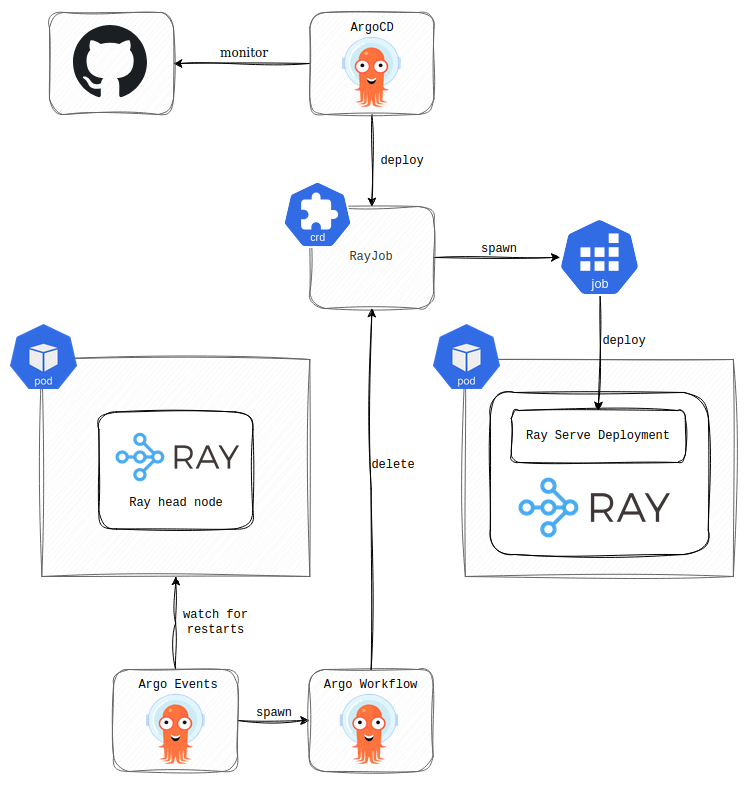
This approach isn’t a silver bullet, as it takes some time to deploy the Ray Serve Deployment with the recreated RayJob CR after the head node restarts. Consequently, this solution also introduces a short outage, but at least we are assured all Ray Serve Deployments will be restored without manual intervention.
In conclusion, we are accustomed to treating and designing applications in the K8s cluster as cattle rather than pets; therefore, having something like RayCluster’s head node without external GCS is not an ideal solution for us. Additionally, the absence of ArgoCD self-healing for the Ray Serve Deployments deployed via the RayJob CR doesn’t contribute to my peace of mind. Nevertheless, the industry is shifting towards AI workloads, so both the people and the technologies must adapt.