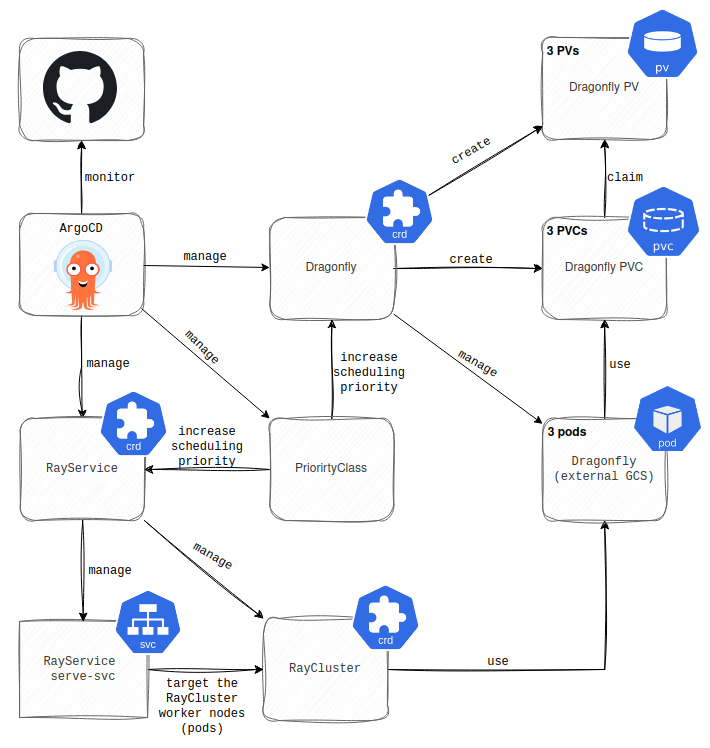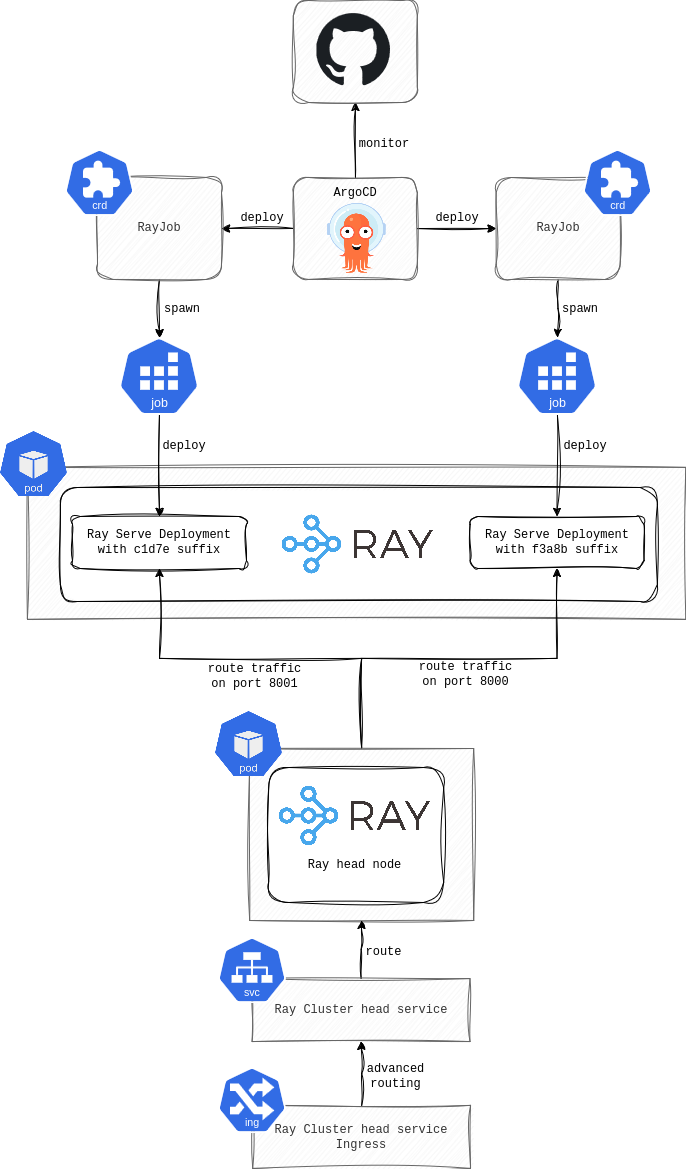
As described in the first part of this series, we set up our CI/CD to deploy an application running as a Ray Serve Deployment to the RayCluster, and came up with a passable workaround for the external Global Control Service (GCS).
Slowly but surely, the production K8s cluster came to life and started providing the application’s services to customers. However, before that happened, we had to address Secret management. As mentioned in the first part, the RayCluster nodes are represented as K8s pods. The basic security recommendation is to store the credentials in a Secret Manager, pull them into the K8s using a dedicated K8s Operator (e.g., external-secrets), and load them into the applications from the K8s Secret resource. However, the RayCluster nodes (pods) live longer than the applications running on them. As a result, deploying a new application version doesn’t roll out RayCluster nodes (pods), and loading new credentials or updating the old ones requires a manual restart of RayCluster nodes (pods). The manual restart didn’t really work for us, so we were left with a couple of options—or rather, just one that truly made sense.
One option was to set the credentials in the runtimeEnvYaml.env_vars of the RayJob CR. This would mean that the Git repository monitored by ArgoCD and dedicated to deployment configuration would contain confidential data. We certainly didn’t want to store the confidential data in the Git repo, so this option was out of the question. Another approach was to configure the pipeline to create the .env file with credentials and bundle it with the source code in the application ZIP file. However, this is similar to the anti-pattern of building the OCI image with the confidential data as plain text in your source code. Eventually, folks from Mixedbread had to update their source code and use a library that loads credentials from the Secret Manager immediately after the application starts.
As usual, problems that you probably never thought of arise along the way. In hindsight, that’s the second-best thing I learned at uni. Paradoxically, right after the first one, “If you’re stuck thinking of a way to implement something, just sit down and start”, but that’s again another story, so let’s get back.
After running in production for a couple of weeks, we wanted to scale up the nodes with GPU devices due to increased load. We rented another GPU instance and connected it smoothly to the K8s cluster. The real trouble began after we scaled up the number of nodes using the GPU in RayCluster. CUDA on a newly created RayCluster GPU node (K8s pod) didn’t recognize the GPU device. Restarting the pod was ineffective. Only rebooting the K8s node running the new RayCluster’s GPU node helped. In the future, however, this small issue will pose a “small” obstacle to setting up autoscaling of RayCluster’s worker nodes that use the GPUs.
On the other hand, autoscaling of the CPU nodes functions well, or does it? Well, on the K8s level, it does, but when it comes to the RayCluster, the downscaling is broken. Looks like this PR in the Ray project will fix the issue, and we’ll need to upgrade the RayCluster after the fix is released.
The thing is, upgrading the RayCluster isn’t as simple as bumping up the version and applying the changes. This approach will cause an outage because, as mentioned in the previous blog post, there’s only one head node, and if other nodes lose the connection to it, they will be restarted.
This means no running applications for a while. In fact, you will experience an outage even before the other RayCluster nodes lose connection to the head node because the head node is the only component that exposes the applications. Will talk more about that later.
We could resolve our RayCluster upgrade issue by migrating to RayService, which is a Custom Resource (CR) that spawns the RayCluster and also deploys the applications there. On top of that, it supports the rolling updates of the RayCluster and exposes the applications targeting all RayCluster nodes. However, it wasn’t an ideal fit for us because it takes some configuration power away from developers.
This would mean the number of Ray Serve Deployment replicas and other settings would have to be defined in the RayService CR instead of the application source code. The developers didn’t really like that, and also wanted to have a clear distinction between RayCluster (“infra”) and RayJob (application). So, we stuck with the RayCluster CR and came up with a manual RayCluster upgrade strategy, where we spawn a new upgraded RayCluster, switch the CI/CD deployment, and eventually redirect the traffic. Then, we decommission the old RayCluster. Looks like everything in life is a trade-off.
We’re sure everyone, or at least most of you, do not deploy the latest application version directly to production. It typically goes through multiple – or at least one – different environments to test and eliminate mistakes. The same is true in our case, but usually, you want to deploy and release new changes gradually. For that, you need to use some form of an advanced deployment (e.g., Canary, Blue/Green, etc.).
When running a usual K8s workload, you can leverage Argo Rollout and obtain these features out of the box. However, it won’t work with KubeRay. The Ray Serve Deployment is deployed using RayJob CR instead of a classic K8s Deployment; therefore, it can’t be replaced by Argo Rollouts. Most importantly, as noted before, the applications in the RayCluster are exposed by the K8s Service that targets only the RayCluster’s head node and is managed by the RayCluster CR.
We haven’t implemented an advanced deployment strategy yet, so the actual approach can’t be shared, but we believe it will eventually be very similar to the following. First, we’ll configure the RayCluster CR to open and expose at least two ports on the head K8s service where the applications can listen. Then, we’ll update the application source code to generate a unique name for the Ray Serve Deployment (probably by adding some random hash suffix) to ensure the RayJob CR deploys a new instance instead of performing a rolling update of the old one. Additionally, the application will have to listen on a different port than the old version, and this port needs to be targeted by the RayCluster’s head Service. Finally, we’ll move out of the RayCluster layer and finalize the advanced routing with other K8s tools (e.g., Nginx Ingress with canary annotations, etc.).
One more thing is worth noting before wrapping up. You can’t view your application logs on the RayCluster’s node (K8s pod’s) stdout. To see them, you must either use the Ray dashboard or deploy a sidecar container on each RayCluster node (K8s pod) that collects the logs for a central logging tool (e.g., Loki).
As you may have noticed, running AI workloads in K8s using the KubeRay Operator differs from running typical K8s workloads with built-in workload resources. This may be because Ray wasn’t initially developed for the K8s, and the KubeRay Operator is doing its best to bridge the gap. The purpose of these blog posts was to share the experience with KubeRay Operator, and its nature, so that you might get a bit armed up before jumping into the world of Ray and RayClusters from the world of traditional K8s.